从源码理解 Kafka 的分区选择策略
Kafka 中将 Topic 分为 partition,消费者从 partition 中消费消息。消息是怎么确定发住哪个 partition 呢?其实默认有两种分区选择策略:
- 消息 key 为空时随机选择
- 消息 key 不为空时,对 key 进行 HASH,然后对分区数取模
源码分析
在 KafkaProducer 的 doSend 方法中调用了以下方法进行分区选择,如果指定了分区,则直接使用指定的分区。如果没有指定则通过默认的 partitioner 来计算出分区。
1 | // org.apache.kafka.clients.producer.KafkaProducer#partition |
默认使用的分区处理类是 DefaultPartitioner,其内的实现如下:
1 | // org.apache.kafka.clients.producer.internals.DefaultPartitioner#partition |
如果提供了 key 值,则用 murmur2 的方法对 key 进行 HASH 并对 numPartitions(Topic 的分区数)取模。
当 Key 为空时,通过 stickyPartitionCache 的 partition 方法计算出分区。StickyPartitionCache 是 Kafka Client 内部的一个类,用于管理 Topic 的分区选择的逻辑和缓存。
1 | // org.apache.kafka.clients.producer.internals.StickyPartitionCache#partition |
indexCache 是一个 ConcurrentHashMap 对象,对应的是 Topic -> Partition 的映射,如果该值不存在则调用 nextPartition 方法选择一个分区并缓存。
1 | // org.apache.kafka.clients.producer.internals.StickyPartitionCache#nextPartition |
第一个分支条件 oldPart == null || oldPart == prevPartition 中:
oldPart == null表示没有分区缓存,对应着新增 topic 或第一次调用的情况oldPart == prevPartition当创建了新的Batch时触发了此方法的情况,对分区缓存进行更新
满足以上条件之一就进入真正选择分区的逻辑。
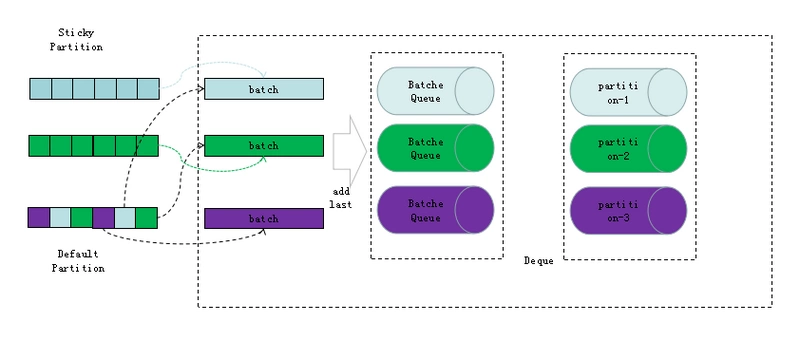
关于 Batch:
- 每个
batch的数据属于同一个partitionSticker Partitioner是 Kafka 对空 key 的分区选择进行的优化,尽量在一个Batch中提交多几条数据。当Batch满或linger.ms时间到
才触发选择新的分区,在这之前,所有消息都会发到缓存的分区。原来的逻辑会每条消息都选择新的分区,可能造成很多batch太小,客户端请求过多,降低呑吐
后面的逻辑根据可用分区数进行处理,决定新的分区:
- 如果无可用分区,从所有分区里随机选择一个分区
- 只有一个可用分区,直接选用该分区
- 多个可用分区,随机取一个不等于当前分区的可用分区
结论
- 消息 key 为空时,如果有缓存分区,使用缓存分区,没有缓存则随机选择
- 消息 key 不为空时,对 key 进行 HASH,然后对分区数取模
参考:
kafka生产者分区优化
Apache Kafka Producer Improvements with the Sticky Partitioner
从源码理解 Kafka 的分区选择策略
https://blog.imoe.tech/2020/03/27/27-kafka-partition-selection-policy/

