SQL 基础
本文整理了常用的 SQL 语句和基本的概念,方便使用时查询。
增删改查 CRUD
插入数据
1 | INSERT INTO user |
插入行的一部分
1 | INSERT INTO user(username, password, email) |
插入查询出来的数据
1 | INSERT INTO user(username) |
更新数据
1 | UPDATE user |
删除数据
1 | DELETE FROM user |
清空表中的数据
1 | TRUNCATE TABLE user; |
查询数据
SELECT语句用于从数据库中查询数据。DISTINCT用于返回唯一不同的值。它作用于所有列,也就是说所有列的值都相同才算相同。LIMIT限制返回的行数。可以有两个参数,第一个参数为起始行,从 0 开始;第二个参数为返回的总行数。ASC:升序(默认)DESC:降序
限制查询结果
1 | -- 返回前 5 行 |
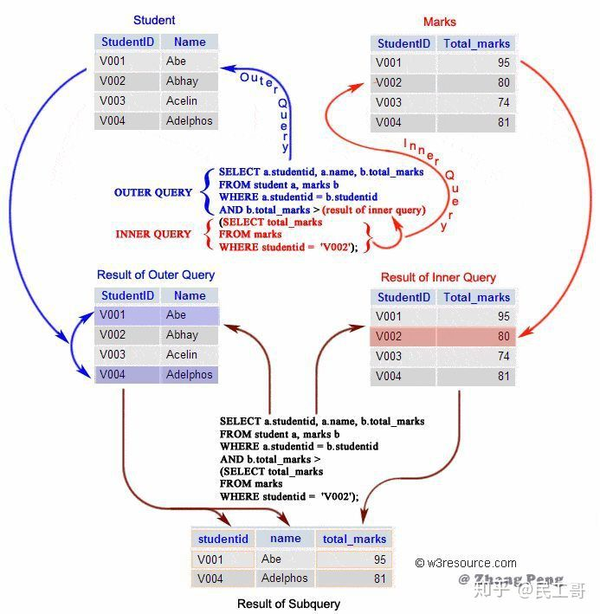
子查询
子查询是嵌套在较大查询中的 SQL 查询。
- 子查询可以嵌套在
SELECT,INSERT,UPDATE或DELETE语句内或另一个子查询中。 - 子查询通常会在另一个
SELECT语句的WHERE子句中添加。 - 您可以使用比较运算符,如
>,<,或=。比较运算符也可以是多行运算符,如IN,ANY或ALL。 - 子查询必须被圆括号
()括起来。 - 内部查询首先在其父查询之前执行,以便可以将内部查询的结果传递给外部查询。
WHERE
WHERE 子句用于过滤记录,即缩小访问数据的范围。
IN 和 BETWEEN
-
IN操作符在WHERE子句中使用,作用是在指定的几个特定值中任选一个值。 -
BETWEEN操作符在WHERE子句中使用,作用是选取介于某个范围内的值。
LIKE
LIKE 操作符在 WHERE 子句中使用,作用是确定字符串是否匹配模式。LIKE 支持两个通配符匹配选项:% 和 _。
%表示任何字符出现任意次数。_表示任何字符出现一次。
连接和组合
连接(JOIN)
JOIN 子句用于把来自两个或多个表的行结合起来,基于这些表之间的共同字段。
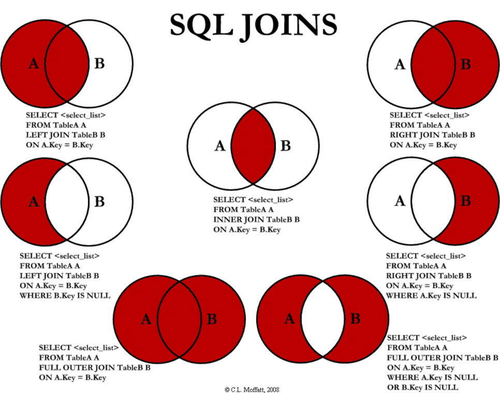
- INNER JOIN:如果表中有至少一个匹配,则返回行
- LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行
- RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行
- FULL JOIN:只要其中一个表中存在匹配,则返回行
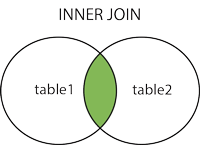
INNER JOIN
关键字在表中存在至少一个匹配时返回行。INNER JOIN 与 JOIN 是相同的。
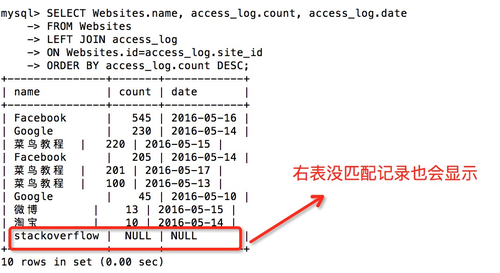
1 | SELECT Websites.name, access_log.count, access_log.date |
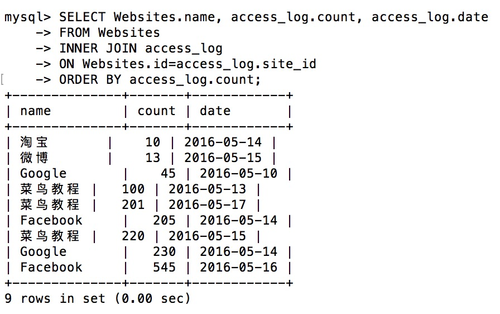
如果 “Websites” 表中的行在 “access_log” 中没有匹配,则不会列出这些行。
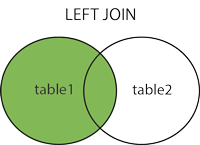
LEFT JOIN
从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。
RIGHT JOIN
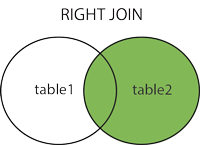
从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。

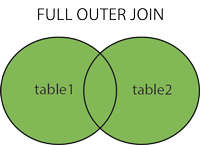
FULL OUTER JOIN
只要左表(table1)和右表(table2)其中一个表中存在匹配,则返回行。
JOIN 总结
- A inner join B 取交集。
- A left join B 取 A 全部,B 没有对应的值为 null。
- A right join B 取 B 全部 A 没有对应的值为 null。
- A full outer join B 取并集,彼此没有对应的值为 null。
组合(UNION)
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
UNION 内部的每个 SELECT 语句必须拥有相同数量的列,列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
1 | SELECT column_name(s) FROM table1 |
UNION操作符选取不同的值(去重)。如果允许重复的值,请使用UNION ALLUNION结果集中的列名总是等于UNION中第一个SELECT语句中的列名
排序和分组
ORDER BY
ORDER BY用于对结果集进行排序。ASC:升序(默认)DESC:降序- 可以按多个列进行排序,并且为每个列指定不同的排序方式
GROUP BY
GROUP BY 子句将记录分组到汇总行中,为每个组返回一个记录。可以按一列或多列进行分组。
GROUP BY 按分组字段进行排序后,ORDER BY 可以以汇总字段来进行排序。
1 | SELECT cust_name, COUNT(cust_address) AS addr_num |
HAVING
HAVING用于对汇总的GROUP BY结果进行过滤。HAVING要求存在一个GROUP BY子句。
数据定义
创建数据表
1 | CREATE TABLE user ( |
修改数据表
添加列
1 | ALTER TABLE user ADD age int(3); |
删除列
1 | ALTER TABLE user DROP COLUMN age; |
修改列
1 | ALTER TABLE `user`MODIFY COLUMN age tinyint; |
索引(INDEX)
创建索引
1 | CREATE INDEX user_index ON user (id); |
创建唯一索引
1 | CREATE UNIQUE INDEX user_indexON user (id); |

