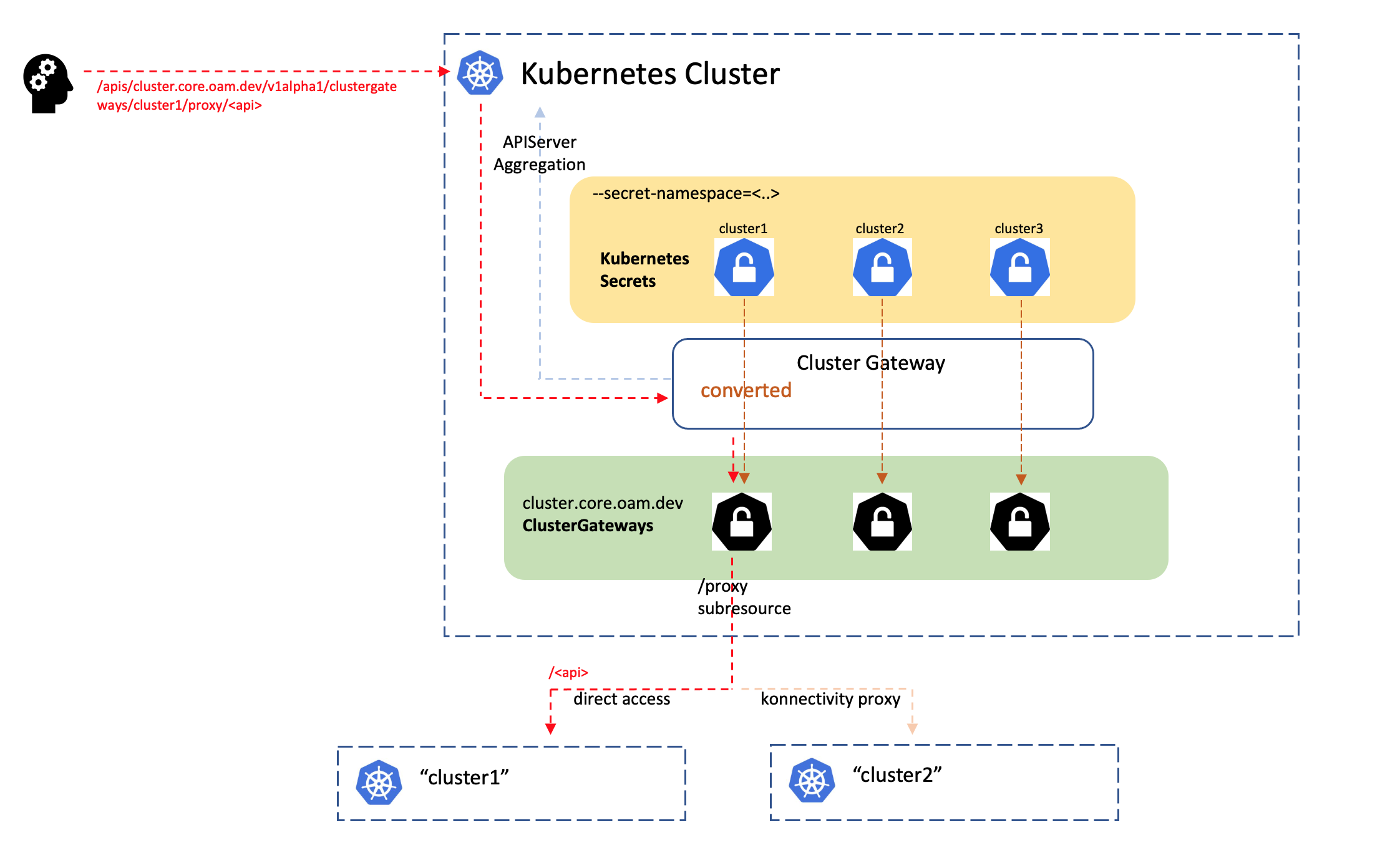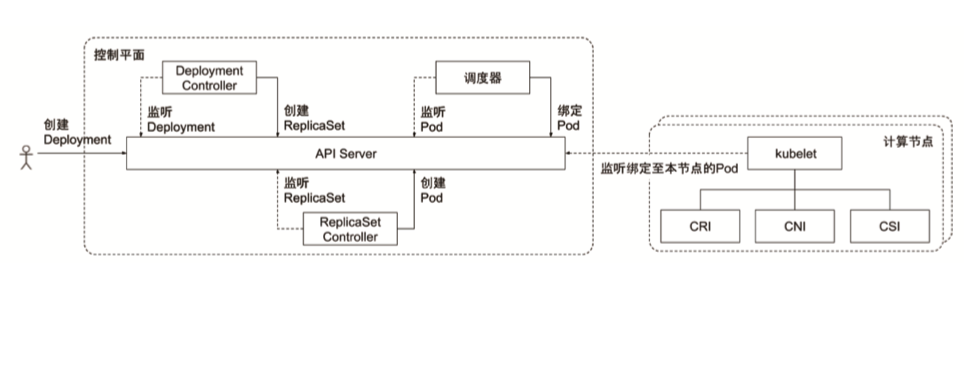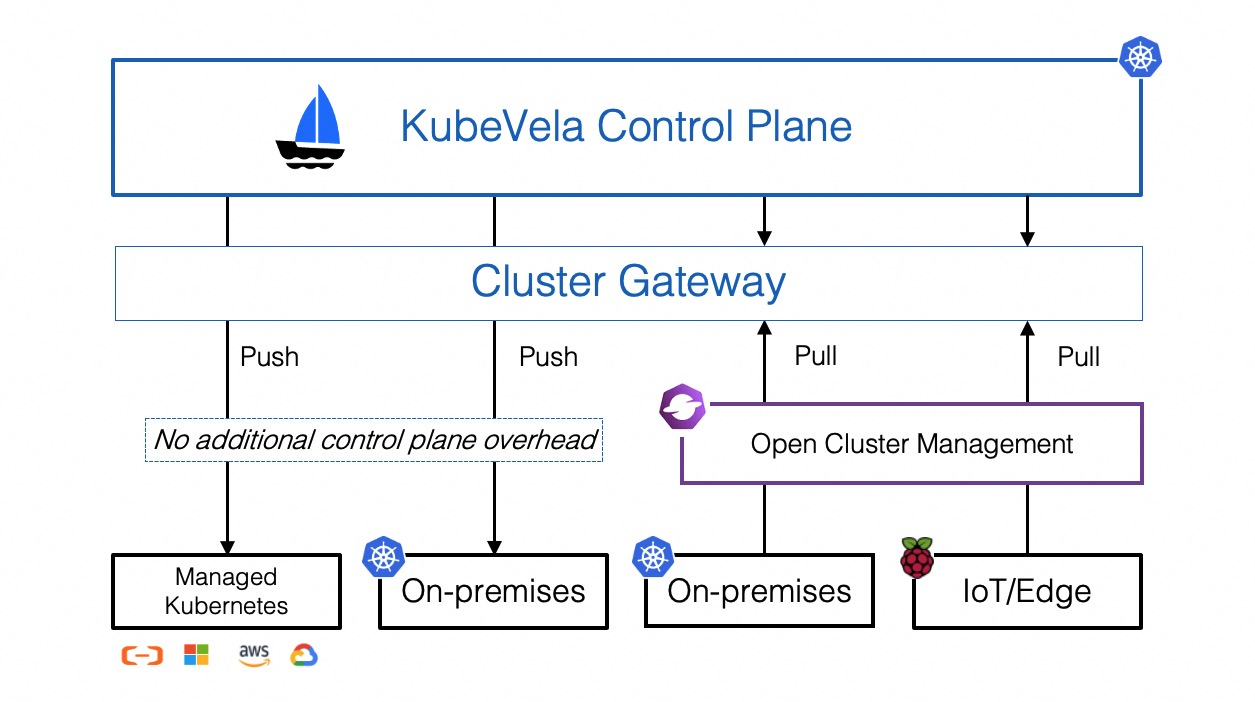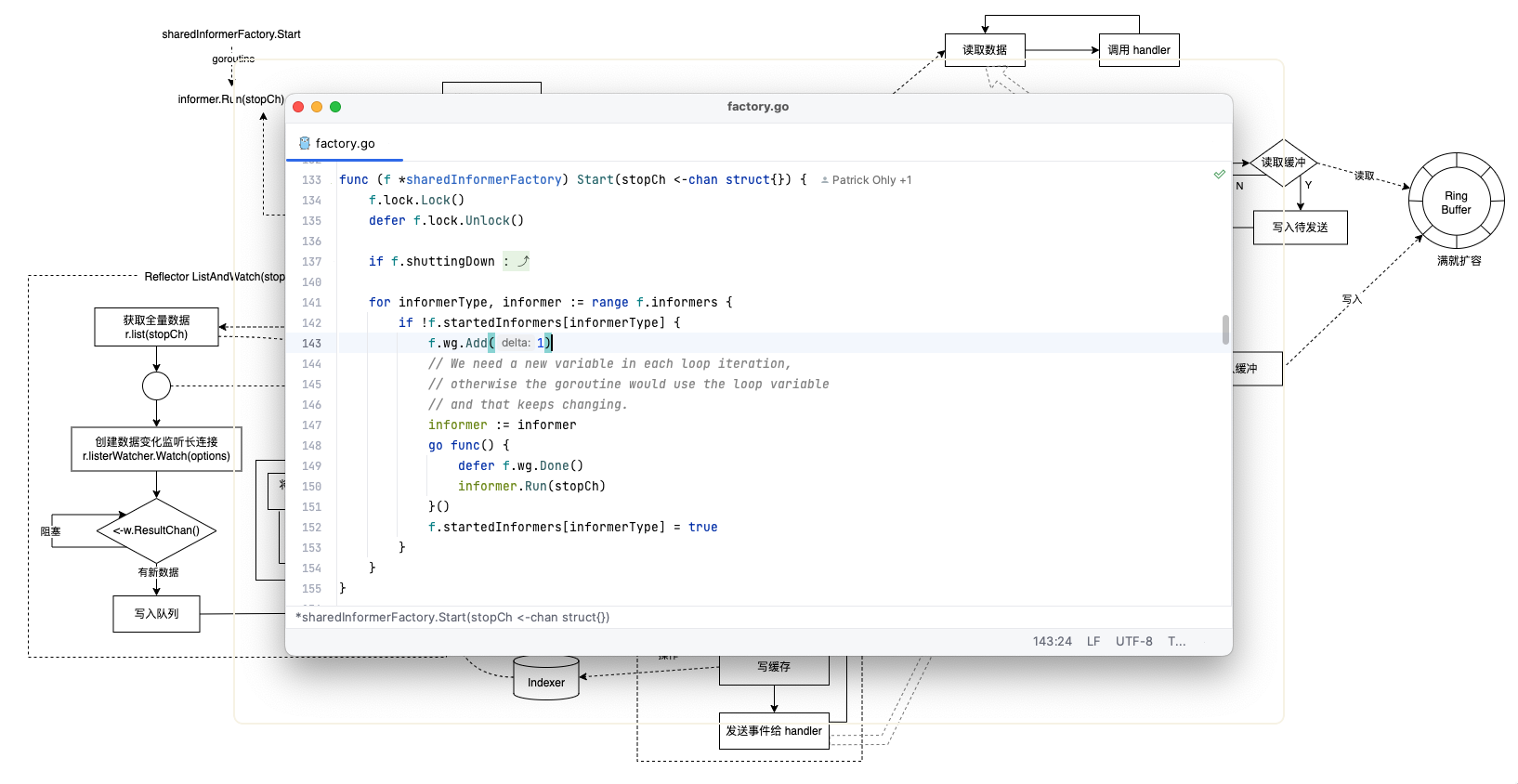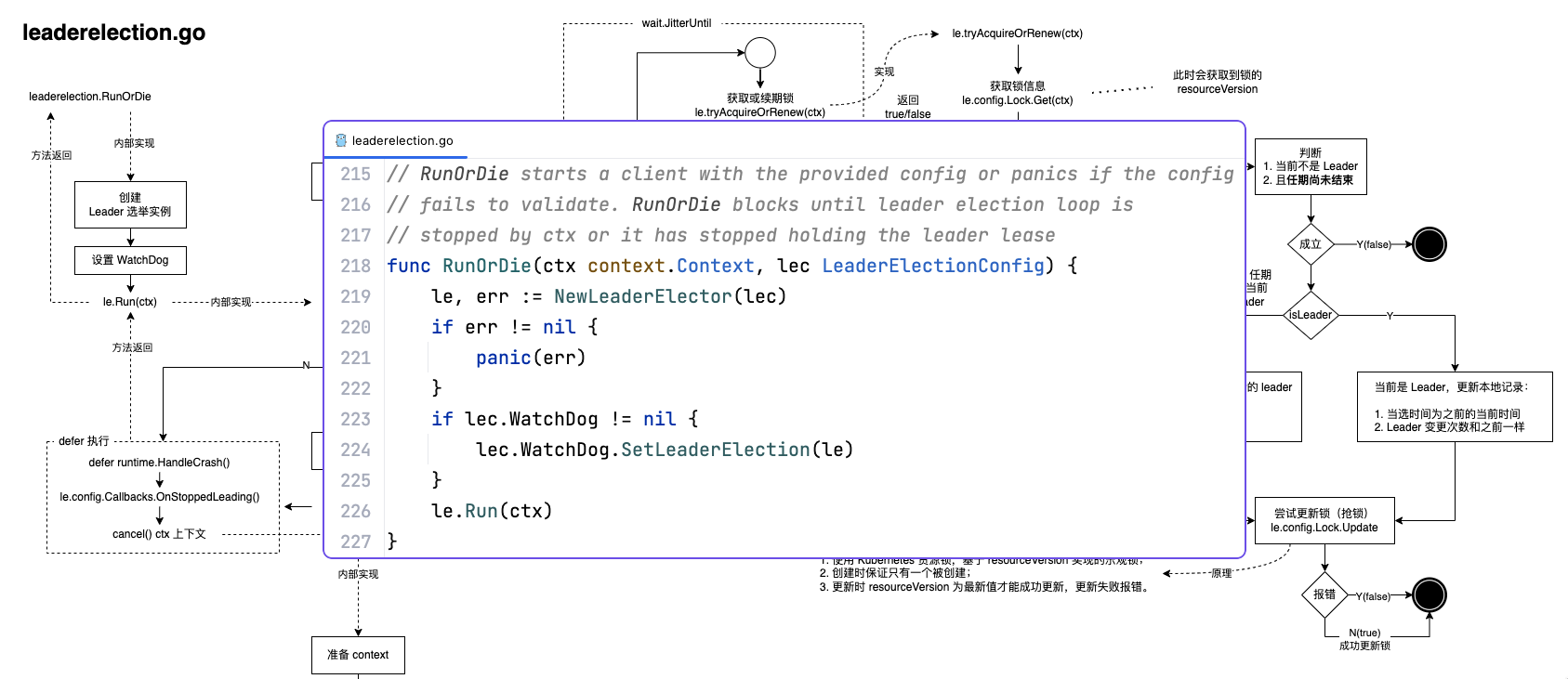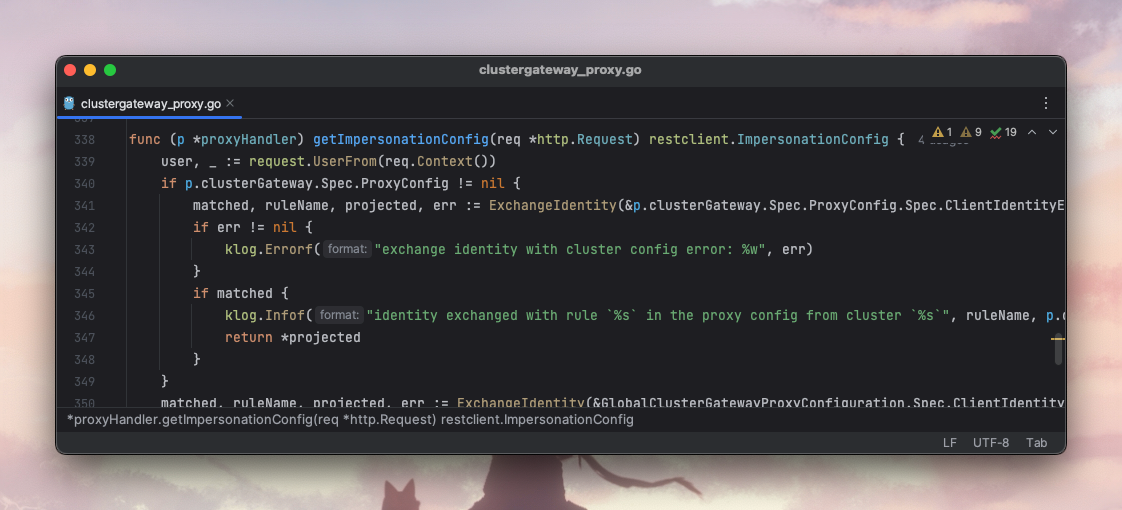
Kubernetes 中的用户伪装功能
用户伪装是 Kubernetes 原生提供的 User impersonation 功能,这个功能在管理集群时非常有用。
通常在管理系统中管理集群时,使用的都是集群管理员(cluster-admin)这样的高权限用户。当用户使用系统进行操作集群时,实际操作身份和集群权限并不匹配,这样很容易造成安全问题。
比如用户实际权限只有 Namespace 的操作,但通过集群管理系统部署 Helm 时,由于管理系统使用的集群管理员用户,如果 Chart 包里创建多个 Namespace 甚至是 ServiceAccount 就会造成越权。
通常会考虑在管理系统中做权限,但相当于有两套权限,很难保证做得面面具到,如果使用 Kubernetes 的用户伪装功能就可以完美解决这个问题。