深入学习 Deployment 实现
Deployment 是 Kubernetes 三个常用工作负载中最常用的。Deployment 用于管理应用的部署情况,可以实现应用的滚动升级和回滚,还能实现应用的扩缩容。
Deployment 通过 ReplicaSet 来管理 Pod。一个完整的 Deployment 创建到 Pod 被拉起的流程由多个控制器协同完成:

Deployment 是 Kubernetes 三个常用工作负载中最常用的。Deployment 用于管理应用的部署情况,可以实现应用的滚动升级和回滚,还能实现应用的扩缩容。
Deployment 通过 ReplicaSet 来管理 Pod。一个完整的 Deployment 创建到 Pod 被拉起的流程由多个控制器协同完成:
UpgradeAwareHandler 是 Kubernetes 里很重要的一个代码组件,在 Kubernetes 中用于代理和转发请求。
只要是有转发请求的地方都可以见到他的身影:
第三方的集群网关组件也会利用这个组件来实现转发代理,如:Karmada、KubeVela Cluster Gateway 等。
为什么都使用这个组件来转发请求?本文通过阅读源码,深入研究这个组件的实现原理以及使用方式。
Kubernetes 是一个声明式的系统。我们在使用 Kubernetes 管理应用、部署服务时,通常会使用一个 YAML 格式的文件去描述期望应用部署后的最终状态。
当这个文件被提交到 Kubernetes 后,我们神奇地发现 Kubernetes 在不停地创建各种资源,直到达到我们所描述的状态。实现这个功能的组件就是我们今天讨论的 kube-controller-manager,Kubernetes 集群的大脑。
我们平时所见到的 Kubernetes 集群中的节点(Node)、Pod、服务(Service)、端点(Endpoint)、命名空间(Namespace)、服务账户(ServiceAccount)、资源定额(ResourceQuota) 等资源都是由 kube-controller-manager 管理的。
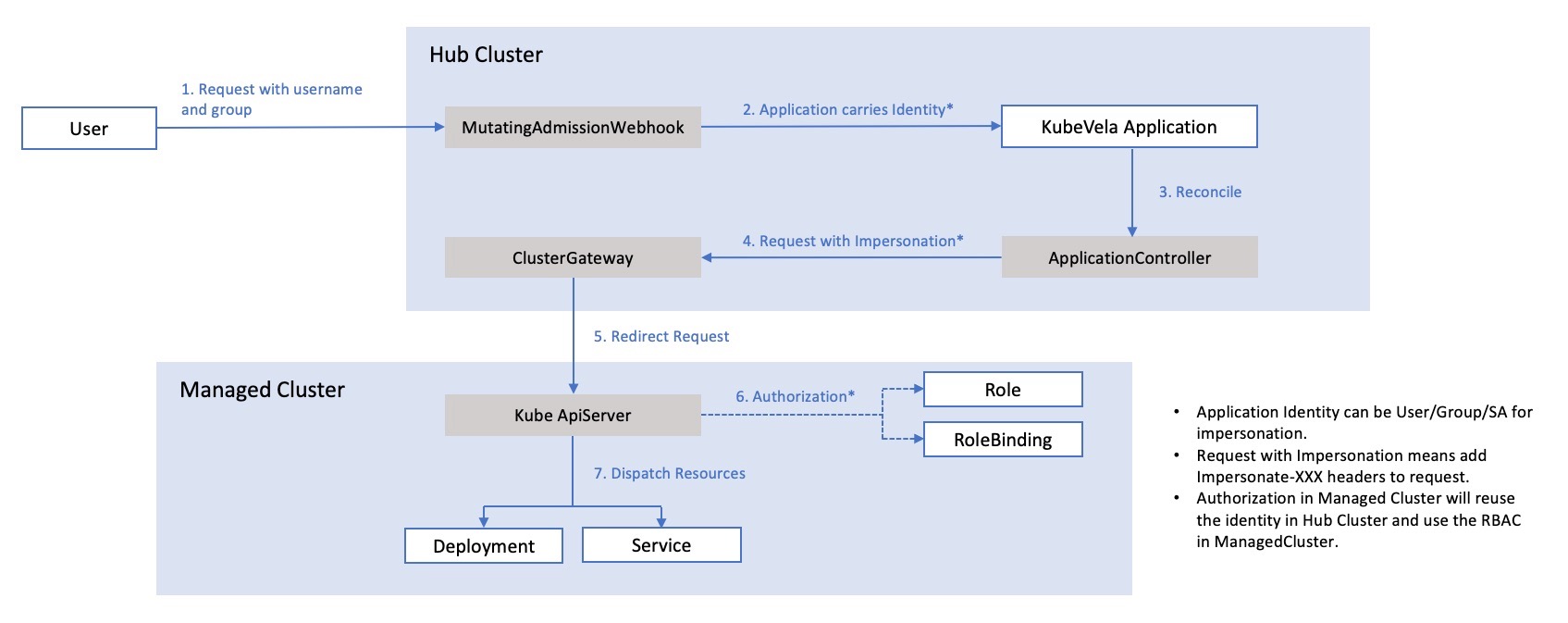
KubeVela 中使用用户伪装功能的主要有两个模块:KubeVela Controller 和 KubeVela API Server。
在 KubeVela 核心组件里有两个和用户伪装相关的功能:应用认证和 ServiceAccount 伪装。VelaUX 由于自身带了一套用户权限相关的功能,当开启用户伪装后,会注入登录的用户信息作为伪装用户。
用户伪装是 Kubernetes 原生提供的 User impersonation 功能,这个功能在管理集群时非常有用。
通常在管理系统中管理集群时,使用的都是集群管理员(cluster-admin)这样的高权限用户。当用户使用系统进行操作集群时,实际操作身份和集群权限并不匹配,这样很容易造成安全问题。
比如用户实际权限只有 Namespace 的操作,但通过集群管理系统部署 Helm 时,由于管理系统使用的集群管理员用户,如果 Chart 包里创建多个 Namespace 甚至是 ServiceAccount 就会造成越权。
通常会考虑在管理系统中做权限,但相当于有两套权限,很难保证做得面面具到,如果使用 Kubernetes 的用户伪装功能就可以完美解决这个问题。
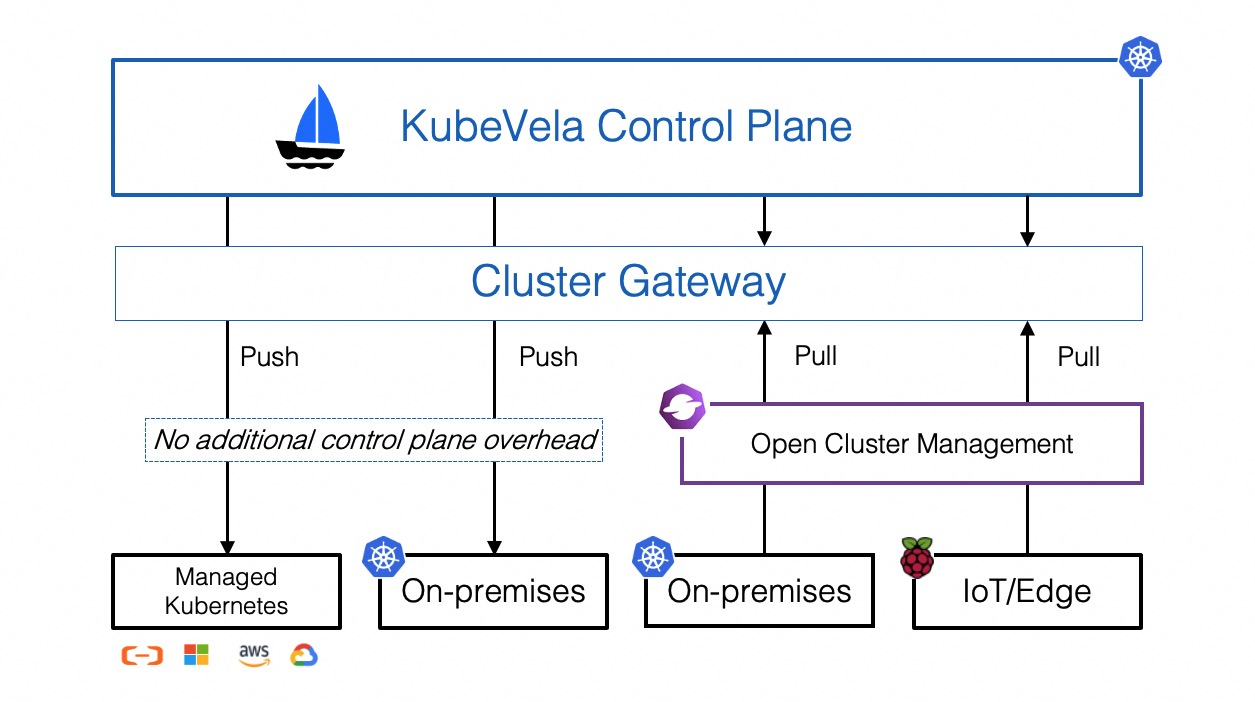
KubeVela 是多集群应用管理组件,所以在使用之前需要将集群纳管到 KubeVela 中,让 KubeVela 能感知并维护集群信息。在应用下发到指定集群时,KubeVela 能知道如何连接到目标集群并进行操作。
KubeVela 使用的是 Secret 来保存集群信息的,和 Cluster Gateway 共享的同一套 Secret 进行集群管理。当进行集群纳管时,KubeVela 会创建名字和集群名相同的 Secret,用于存储集群的连接信息。
当请求从 APIServer 转发到 Cluster Gateway 时,使用路径中提供的集群名去查询 Secret 并获取到纳管集群的连接信息。
Cluster Gateway 处理流程如下:
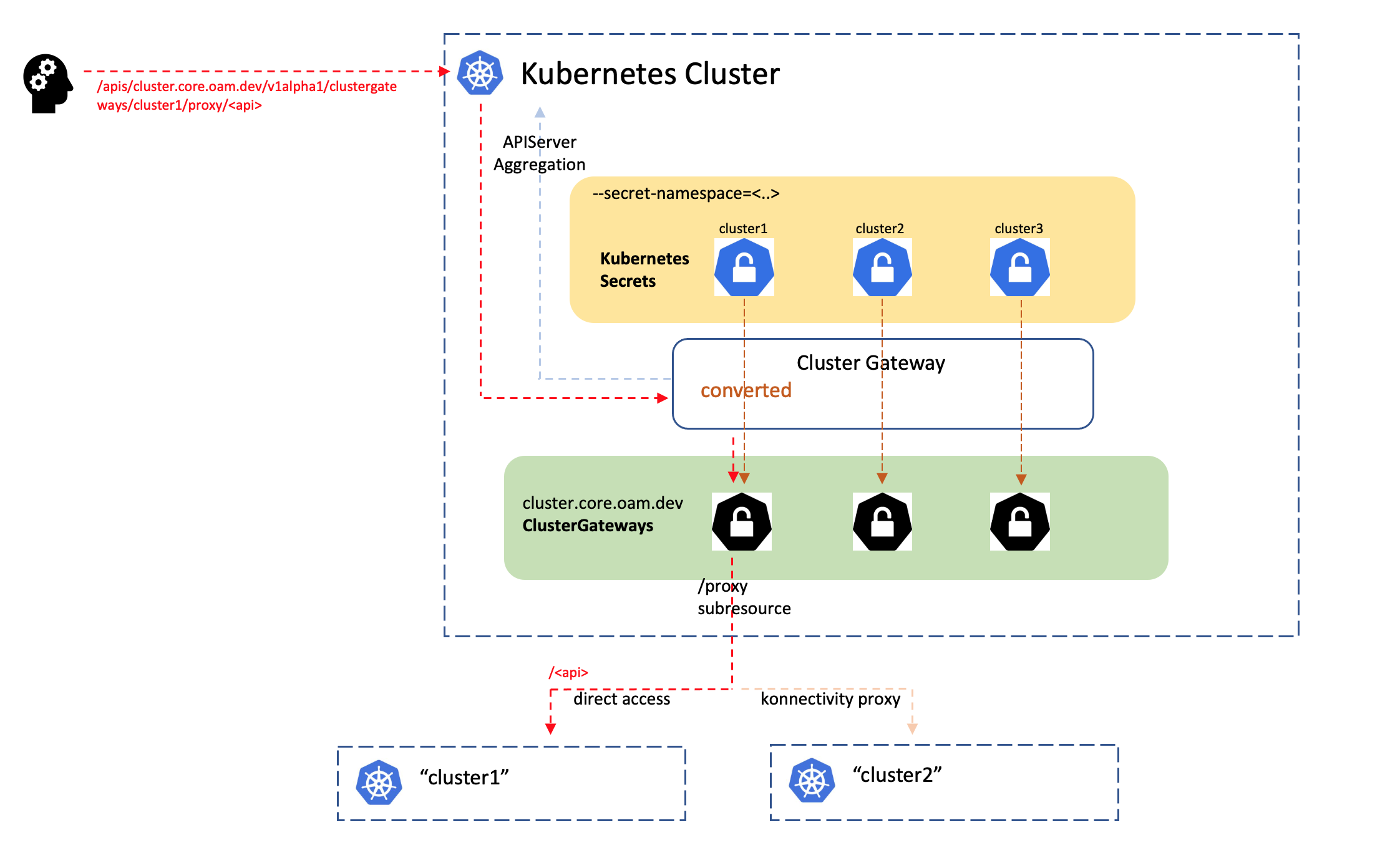
KubeVela 的多集群管理依赖于 Cluster Gateway 组件,在 KubeVela 的 Helm Chart 中会自动安装。KubeVela 并不会直连集群,而是必须通过 Cluster Gateway 连接集群进行管理。
包括集群管理在内的功能都是依赖于 Cluster Gateway 实现的,所以 Cluster Gateway 是 KubeVela 多集群管理必不可少的一个组件。
在 Kubernetes 中,kube-apiserver 是整个集群的大脑和心脏,是控制集群的入口,所有模块都是通过其提供的 HTTP REST API 接口来操作集群的。
由于是所有模块的数据交互和通信的枢纽,大量组件直接通过 HTTP 请求 apiserver 带来的访问压力是非常大的。一但 apiserver 出现异常,整个集群就会受到影响,甚至崩溃。
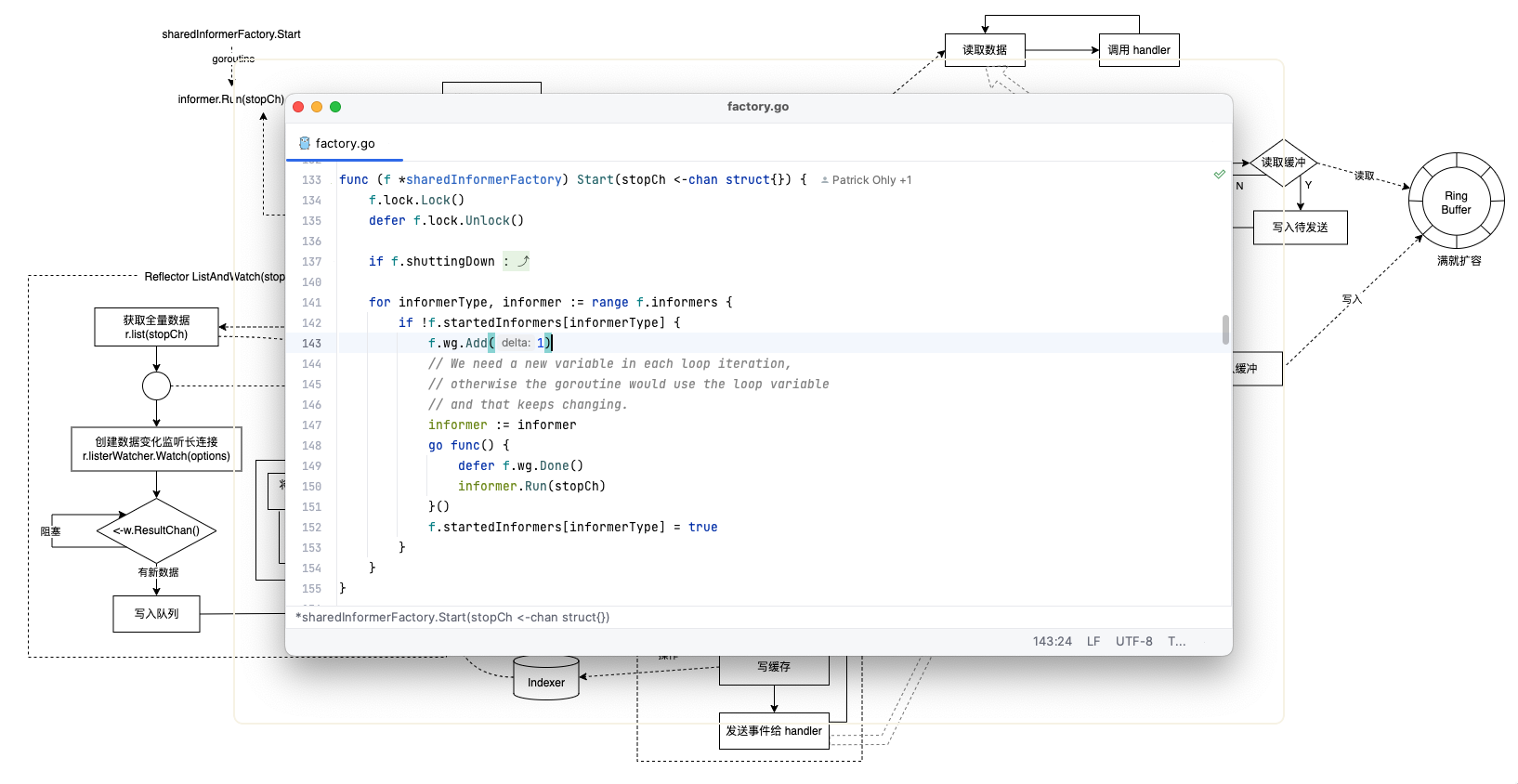
所以尽可能降低 apiserver 的访问压力是很有必要的,Informer 机制就是 Kubernetes 解决这个问题的方案。Informer 本质就是 client-go 提供的一种本地缓存机制:
通过 Informer 机制,大大降低了 Kubernetes 各个组件跟与 API Server 的通信压力,同时 ETCD 的查询压力也同样得到缓解。
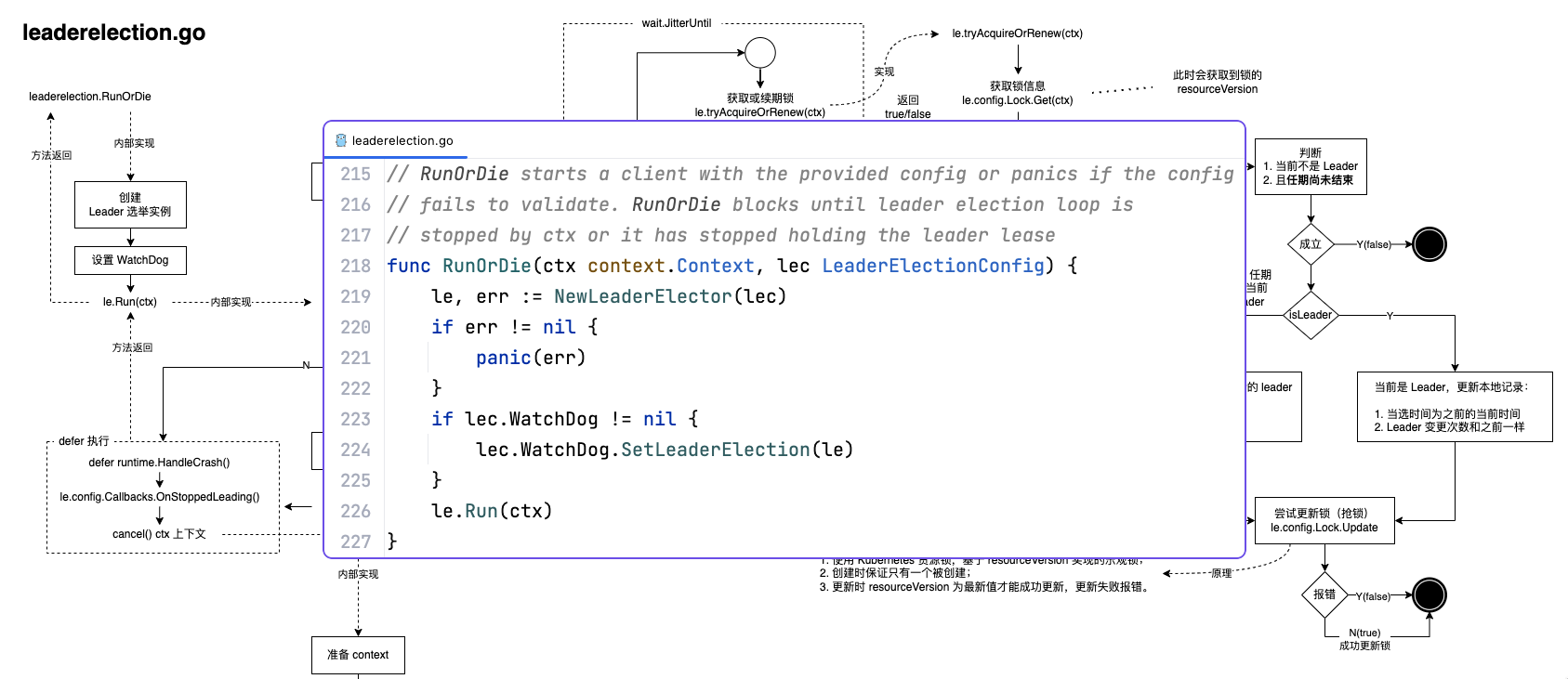
Kubernetes 内部很多核心组件是有状态的,都以一主多从多实例的方式运行。这些组件的一主多从中,只有主实例负责处理数据,从实例处在热备状态。当主实例异常时从实例将竞选成为主实例并接替进行任务处理,所以这个选举机制是 Kubernetes 对于这有状态组件高可用的保障。
核心组件如 kube-scheduler 或 kube-controller-manager 等组件,在同一时刻只有一个实例在处理业务逻辑,因此需要在启动的实例中进行选主,决定哪个实例负责处理任务。这些核心组件都是使用的 client-go 中提供的工具类 leaderelection,也就是本文的主角。
leaderelection 依赖于 Kubernetes 中提供的 Endpoints、ConfigMap 和 Lease 三种资源锁,leaderelection 选主的实现方式就是基于这三种资源锁:
除了能在核心组件中使用,这个组件也能使用在我们开发的应用中,前提是我们的应用运行在 Kubernetes 环境且有操作资源锁的权限。